Single Cluster Cross-Data Center High Availability Deployment¶
Scenario Requirements¶
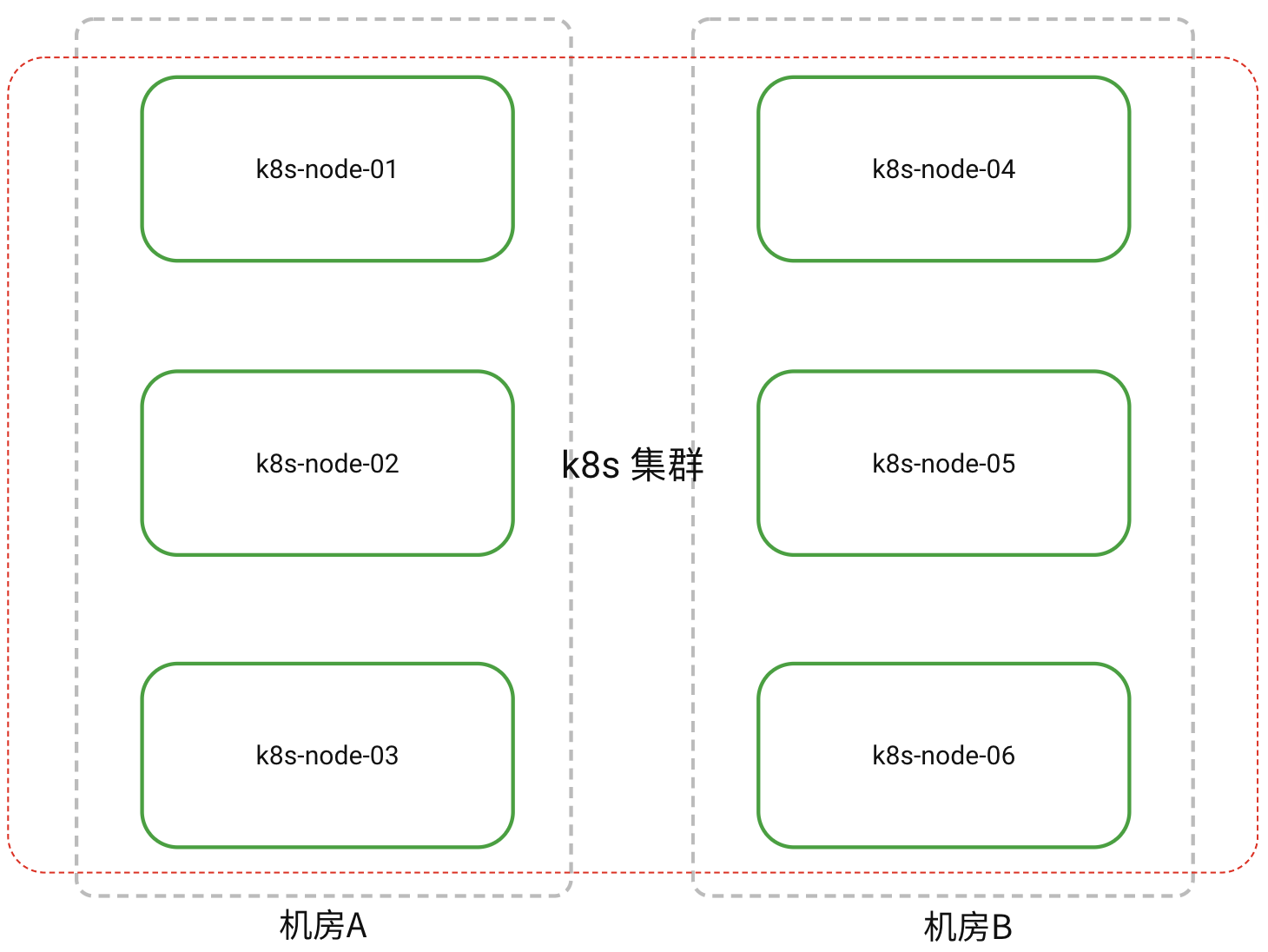
The customer data center environment consists of a single k8s cluster spanning across Data Center A and Data Center B. They wish to deploy a set of 3 masters and 3 slaves of RocketMQ to achieve cross-data center service high availability. When one entire data center goes offline, RocketMQ should still be able to provide services.
RocketMQ 5.1.4 Component Image Addresses¶
docker pull ghcr.io/ksmartdata/rocketmq-controller:v5.1.4
docker pull ghcr.io/ksmartdata/rocketmq-nameserver:v5.1.4
docker pull ghcr.io/ksmartdata/rocketmq-broker:v5.1.4
Solution¶
In RocketMQ 5.0, the broker high availability automatic master/slave switch capability is achieved through the Dledger controller. This mode uses an independent controller to implement the master/slave switch, and the broker nodes do not need to follow the CRAFT protocol. Even if less than half of the masters are available, elections can still take place.
DCE Data Services do not currently support RocketMQ 5.0, please operate manually
- After creating the RocketMQ cluster, manually change the
.spec.clusterModein the broker cr from STATIC to CONTROLLER (after the modification, the operator should create a broker pod in controller mode); - Delete the broker pod and pvc generated in STATIC mode (pod names containing master and replica).
The newly created broker pod in CONTROLLER mode does not contain the words master and replica in its name.
Combining the capabilities of the Dledger controller, follow these deployment designs:
- Ensure that the 6 brokers are distributed across different cluster nodes;
- Ensure that each pair of master/slave brokers are distributed in different data centers;
- Try to establish a 1:2 relationship between the master brokers in the two data centers to avoid all masters running in the same data center;
- Ensure that there are replicas of the name_srv in both data centers.
This solution adopts a workload scheduling strategy to achieve the deployment goals through node affinity strategies with weights and workload anti-affinity strategies.
Info
Please ensure that the resources of each node are sufficient to avoid scheduler errors due to insufficient resources.
Steps¶
Configurations¶
-
Enter the following configuration parameters during creation:
-
After creation, modify the CR and restart the broker sts:
apiVersion: rocketmq.apache.org/v1alpha1 kind: Controller metadata: name: controller namespace: mcamel-name-work6 spec: controllerImage: ghcr.io/ksmartdata/rocketmq-controller:v5.1.4 hostPath: /data/rocketmq/controller imagePullPolicy: IfNotPresent resources: limits: memory: 2Gi requests: memory: 2Gi size: 1 storageMode: StorageClass # Remember to modify this volumeClaimTemplates: - metadata: name: controller-storage spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi
Labels¶
RocketMQ Workload Labels
Broker labels are used for workload anti-affinity (built-in labels, no need to configure):
| RocketMQ Group | Workload | Label |
|---|---|---|
| group-0 | broker-0-0/broker-0-1 | broker_cr:{RocketMQ Name} |
| group-1 | broker-1-0/broker-1-1 | broker_cr:{RocketMQ Name} |
| group-2 | broker-2-0/broker-2-1 | broker_cr:{RocketMQ Name} |
Cluster Node Labels
To allocate brokers as expected in two data centers, different labels are configured for the nodes in each data center to ensure that master/slave brokers are placed in different data centers.
| Topology Domain | Cluster Node | Label | |
|---|---|---|---|
| az | Data Center A | k8s-node-01 | az:az1 |
| k8s-node-02 | az:az1 | ||
| k8s-node-03 | az:az1 | ||
| Data Center B | k8s-node-04 | az:az2 | |
| k8s-node-05 | az:az2 | ||
| k8s-node-06 | az:az2 |
Scheduling¶
- RocketMQ uses 1 CR to create 6 broker sts (3 master 3 slave), so each broker instance needs a separate affinity strategy.
- Each pair of brokers (broker-x-0 and broker-x-1) serve as one group, one as master and the other as slave, but there are no labels to identify the roles. Therefore, the goal is to have each group of two brokers running in different data centers to ensure that masters and slaves are in different data centers.
- Observing that the operator creates brokers in order, it is important to avoid all masters being scheduled in the same data center.
The configuration is as follows:
-
Workload: broker-0-1 / broker-1-1 / broker-2-0
# Execute workload anti-affinity to ensure only one broker replica is scheduled per cluster node. affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: broker_cr operator: In values: - {RocketMQ Name} topologyKey: kubernetes.io/hostname # Preferably deploy in Data Center A, usually the first registered sts in each group will serve as master nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 preference: matchExpressions: - key: az operator: In values: - az1 - weight: 90 preference: matchExpressions: - key: az operator: In values: - az2 -
Workload: broker-0-0 / broker-1-0 / broker-2-1
# Execute workload anti-affinity to ensure only one broker replica is scheduled per cluster node. affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: broker_cr operator: In values: - {RocketMQ Name} topologyKey: kubernetes.io/hostname # Reverse scheduling priority with sts in the same group to avoid scheduling in the same data center nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 preference: matchExpressions: - key: az operator: In values: - az2 - weight: 90 preference: matchExpressions: - key: az operator: In values: - az1 -
Workload: namesrv
# Two replicas, deploy one namesrv in each data center, the absence of an online namesrv will cause broker work abnormalities. affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: name_service_cr operator: In values: - {namesrv Name} topologyKey: az -
Workload: controller (optional)
# Single replica, if Data Center A is the primary business provider, it can be preferentially deployed in Data Center B, this configuration depends on the specific business situation. nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 preference: matchExpressions: - key: az operator: In values: - az2 - weight: 90 preference: matchExpressions: - key: az operator: In values: - az1
Handling Data Center Outages¶
Through the above deployment method, the 3 master/slave groups will deploy master/slave brokers in different data centers.
Data Center A¶
The controller runs in Data Center B. Based on the Dledger controller's master/slave switch mechanism, Data Center B's broker slave -> master can automatically upgrade without manual intervention.
Data Center B Offline¶
- If the controller responsible for scheduling goes offline in Data Center B, the slave -> master conversion will temporarily fail, and manual deletion of the Pod to drift to other nodes will be necessary.
- The controller needs to be rescheduled to existing nodes before the Data Center A's slave -> master automatic upgrade can continue.
Some Considerations¶
- Broker role upgrade failure: Through actual testing, the controller's stability is not very good, and there is a chance of failure in the slave -> master automatic upgrade of brokers. This issue can be resolved by restarting the controller.
-
Be cautious when using the delete operation of the sts: Deleting and rebuilding brokers will cause the scheduling strategies configured in the instances to be lost, but the strategies configured in the CR will not be lost. Therefore, it is recommended to use the delete operation with caution. The restart operation of the sts will not cause the above loss situation.
-
Data Center offline causing console data unavailability: If a 2-replica console is used, an offline data center may cause the console to fail to connect to the name_srv.
Solution: Restart the existing console workload.
-
Viewing broker lists with dashboard issues: If the dashboard is inaccessible, broker list information can be obtained through other methods. It is recommended to use the following methods to view node distribution immediately after deployment to ensure it meets expectations.
-
Method 1: Enter the name_srv Pod and execute the following command:
```bash ./mqadmin clusterList -n 127.0.0.1:9876 ````

- BID = 0: Indicates that the node is a Master
- BID <> 0: Indicates that the node is a slave
-
Method 2: Enter the controller and execute the following command:
-