Karmada Failover Explained¶
Author: Fish-pro

In the multicloud era, how to achieve high availability of applications across data centers, availability zones, and clusters has become a new topic we discuss. In a single cluster, if the cluster fails, all applications in the cluster will be inaccessible. Is there a way to help us automatically migrate the application to a new cluster when the cluster fails, so as to ensure the continuous external access of the application? Obviously, Karmada, as the most popular multicloud project in the community, provides such a capability.
Karmada (Kubernetes Armada) enables users to run cloud native applications across multiple clusters without changing existing applications. Enables a truly open multicloud by providing advanced scheduling capabilities using Kubernetes-native APIs. Karmada It aims to provide convenient automation for multicluster application management in multicloud and hybrid cloud cases, with key features such as centralized multicloud management, high availability and fault recovery. This article is based on Karmada's release version v1.4.2, and we will explore with you how Karmada's cross-cluster fault recovery is realized, Which controllers and schedulers are involved in this process, and what capabilities each controller undertakes in this process, and what capabilities the scheduler undertakes, And how to ensure high availability and continuity of user business?
If you have not known or used Karmada before reading this article, it is recommended to read:
- Karmada Official Documentation
- Cloud Native multicloud Application Tool -- Karmada Overview
- Cloud native multicloud application tool -- Karmada controller
- Cloud Native multicloud Application Tool -- Karmada Scheduler
Why failover is needed¶
First of all, let's sort out the necessity of implementing failover:
- Admins deploy offline applications on the Karmada control plane and distribute Pod instances to multiple clusters. When a cluster fails, administrators want Karmada to migrate Pod instances in the failed cluster to other clusters that meet the conditions.
- Ordinary users deploy online applications in the cluster through the Karmada control plane. Applications include database instances, server instances, and configuration files. At this point, the cluster fails. A customer wishes to migrate the entire application to another suitable cluster. During the application migration process, ensure that the business is not interrupted.
- After the administrator upgrades the cluster, the container network and storage devices used as infrastructure in the cluster will change. The administrator wants to migrate the applications in the cluster to other suitable clusters before upgrading the cluster. During the migration process, services must continue to be provided.
Karmada failure recovery example¶
Karmada failback supports two methods:
- Duplicated (full scheduling strategy). When the number of unscheduled candidate clusters meeting the pp (propagationPolicy) limit is not less than the number of failed scheduling clusters, reschedule the failed clusters to candidate clusters.
- Divided (replica split scheduling policy). In the event of a cluster failure, the scheduler and controller cooperate to attempt to migrate copies of the failed cluster to other healthy clusters.
This article uses Divided as an example:
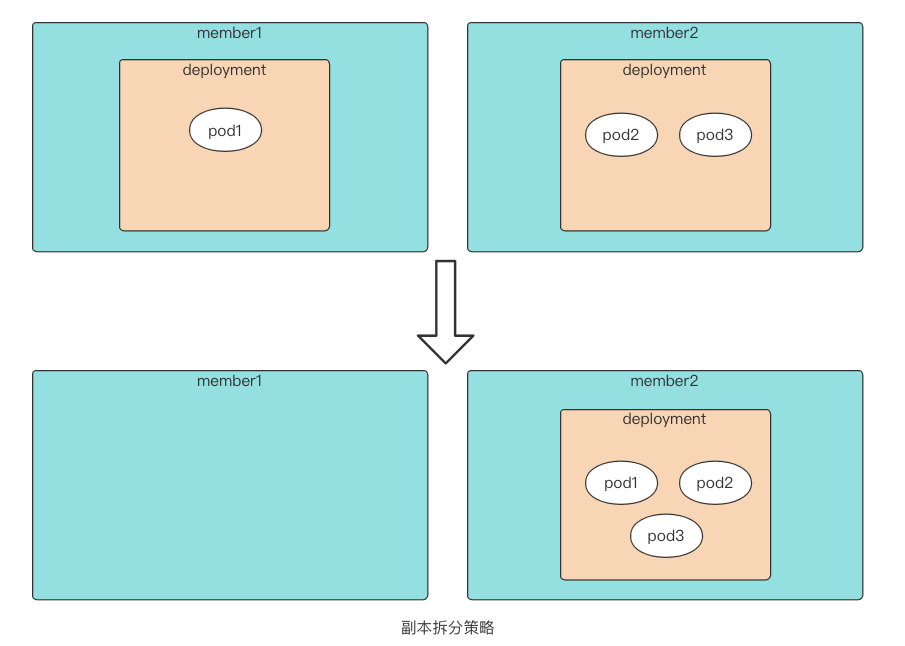
-
After downloading the official Karmada v1.4.2 source code, use hack/local-up-karmada.sh to start the local Karmada. After startup, three working clusters are automatically managed, among which clusters member1 and member2 use push mode, and member3 uses pull mode.
-
Deploy the following application configuration on the Karmada control plane. It can be found that we have defined an nginx application with 3 replicas and a propagation strategy. In the propagation strategy, the cluster affinity is specified by clusterNames , which needs to be scheduled to cluster member1 and member2. At the same time, in the replica scheduling strategy, the replica splitting method is used for scheduling, and the scheduling follows the static weight method of member1 with a weight of 1 and member2 with a weight of 2.
apiVersion: apps/v1 kind: Deployment metadata: name: nginx labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx name: nginx --- apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: nginx-propagation spec: resourceSelectors: - apiVersion: apps/v1 kind: Deployment name: nginx placement: clusterAffinity: clusterNames: -member1 -member2 replicaScheduling: replicaDivisionPreference: Weighted replicaSchedulingType: Divided weightPreference: staticWeightList: - targetCluster: clusterNames: -member1 weight: 1 - targetCluster: clusterNames: -member2 weight: 2After the application is delivered, we will see the following results. A deployment with a copy number of 1 is propagated on the cluster member1, and a deployment with a copy number of 2 is propagated on the cluster member2. A total of three copies meet our scheduling expectations. Check the resource information of the control plane, and find that the corresponding work has been created under the corresponding execution namespace of the member clusters of the control plane. The work here is the carrier of the resource object that actually needs to be propagated on the member clusters after the propagation strategy and coverage strategy are applied. At the same time, it can be seen from the rb (ResourceBinding) of the resource deployment that the deployment is scheduled to cluster member1 and cluster member2.
NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx 3/3 3 3 2m NAME AGE propagationpolicy.policy.karmada.io/nginx-propagation 119s... spec:clusters: - name: member2 replicas: 2 - name: member2 replicas: 1 replicas: 3 resource: apiVersion: apps/v1 kind: Deployment name: nginx namespace: default resourceVersion: "5776" uid: 530aa301-760a-48a7-ada0-fc3a2112564b ... -
The simulated cluster fails. Since the installation cluster is started using kind, we directly suspend the container of the cluster member1. In the simulated actual situation, the cluster loses connection in the federation due to problems with the network or the cluster itself.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8794507af450 kindest/node:v1.23.4 "/usr/local/bin/entr…" 52 minutes ago Up 51 minutes 127.0.0.1:40000->6443/tcp member2-control-plane cc57b0eb54fe kindest/node:v1.23.4 "/usr/local/bin/entr…" 52 minutes ago Up 51 minutes 127.0.0.1:35728->6443/tcp karmada-host-control-plane 5ac1815cd40e kindest/node:v1.23.4 "/usr/local/bin/entr…" 52 minutes ago Up 51 minutes 127.0.0.1:39837->6443/tcp member1-control-plane f5e5f753dcb8 kindest/node:v1.23.4 "/usr/local/bin/entr…" 52 minutes ago Up 51 minutes 127.0.0.1:33529->6443/tcp member3-control-planeIf the suspension is successful, let's look at the actual situation again. We can find that after the cluster suspension is successful, the resource template status of the control plane is still '3/3', which is in line with the overall expectation. Get the deployment on the member cluster, the cluster member1 network is unreachable. The deployment with 3 replicas is obtained on the cluster member2, and a new replica is added to the cluster member2 after the fault occurs. After viewing the Karmada resource rb (rersourcebinding) and pp(propagationPolicy), it can be found that after the failover, the resource binding of the deployment is only scheduled to the cluster member2. But there is a problem. From the configuration of rb (rersourcebinding), we can see that resources are not scheduled to cluster member1 at this time, but there are still corresponding execution namespaces corresponding to cluster member1. work, why is this? Don't worry, let's continue to explore further.
NAME VERSION MODE READY AGE member1 v1.23.4 Push False 43m member2 v1.23.4 Push True 43m member3 v1.23.4 Pull True 42mNAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx 3/3 3 3 11m NAME AGE propagationpolicy.policy.karmada.io/nginx-propagation 11mNAME CLUSTER READY UP-TO-DATE AVAILABLE AGE ADOPTION nginx member2 3/3 3 3 12m Y error: cluster(member1) is inaccessible, please check authorization or networkNAME CLUSTER READY STATUS RESTARTS AGE nginx-85b98978db-8zj5k member2 1/1 Running 0 3m18s nginx-85b98978db-d7q92 member2 1/1 Running 0 12m nginx-85b98978db-xmbp9 member2 1/1 Running 0 12m error: cluster(member1) is inaccessible, please check authorization or network... spec: clusters: - name: member2 replicas: 3 replicas: 3 resource: apiVersion: apps/v1 kind: Deployment name: nginx namespace: default resourceVersion: "5776" uid: 530aa301-760a-48a7-ada0-fc3a2112564b ...Restoring the state of the cluster and simulating the situation where the cluster is repaired by the operation and maintenance administrator, what will happen to the copy at this time? It can be found that when the faulty cluster recovers, the number of replicas on the cluster member2 remains unchanged, and at the same time, the control plane is in the cluster The work under the execution namespace corresponding to member1 is deleted, and the deployment on the cluster member1 is deleted.
NAME VERSION MODE READY AGE member1 v1.23.4 Push True 147m member2 v1.23.4 Push True 147m member3 v1.23.4 Pull True 146mNAME CLUSTER READY STATUS RESTARTS AGE pod/nginx-85b98978db-2p8hn member2 1/1 Running 0 73m pod/nginx-85b98978db-7j8xs member2 1/1 Running 0 73m pod/nginx-85b98978db-m897g member2 1/1 Running 0 70m NAME CLUSTER READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx member2 3/3 3 3 73m```shel(images kubectl get work | grep nginx
From the above example, we can find that when the cluster fails, Karmada will automatically adjust the replicas on the remaining member clusters, So as to meet the user's overall copy expectations, so as to achieve cluster-level failure recovery. When the failed cluster recovers, the transferred copy will remain unchanged, The resources on the original scheduling cluster will be deleted, and the resources will not be scheduled back to the failed cluster.
Karmada fault recovery implementation principle¶
In a multicluster scenario, user applications may be deployed in multiple clusters to improve high availability of services. In Karmada, when a cluster fails or the user does not want to continue running applications on the cluster, the cluster state is marked as unavailable and two taints are added. (images(images When a cluster failure is detected, the controller removes the application from the failed cluster. The removed applications will then be scheduled to other clusters that meet the requirements. In this way, failover can be realized to ensure high availability and continuity of user services.
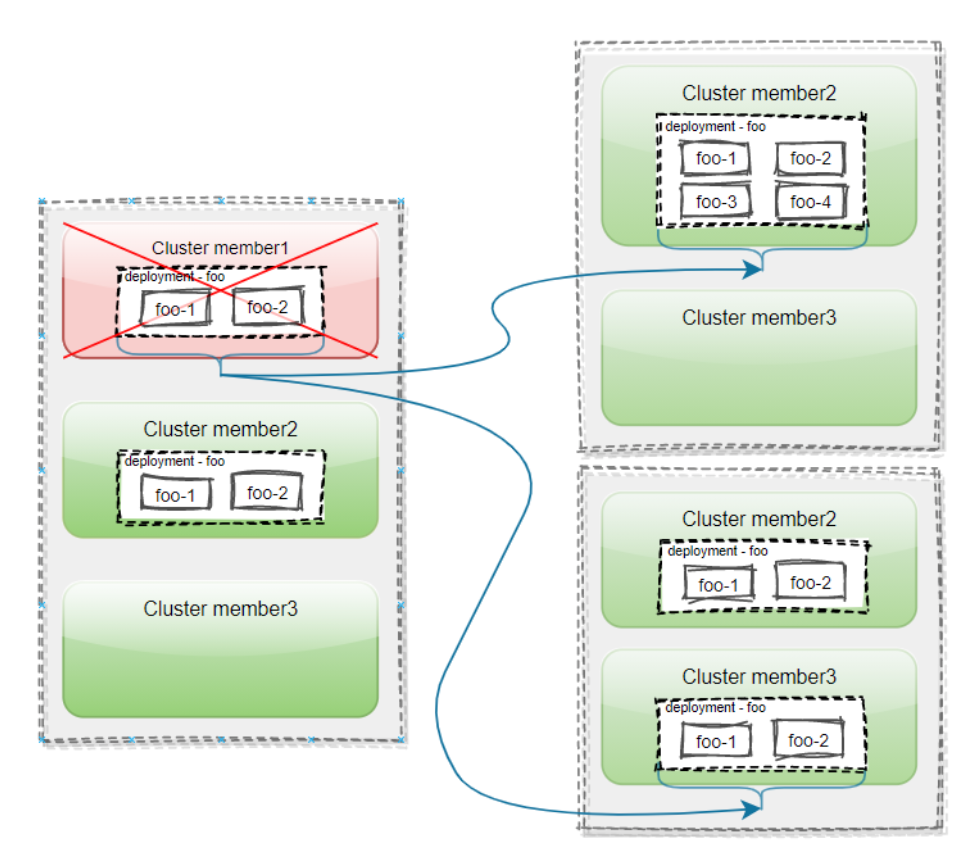
Source: Karmada official document https://karmada.io
As shown above, the user has joined three clusters in Karmada: member1, member2 and member3. Deploy a deployment called foo with two replicas, created on the Karmada control plane. Propagate the deployement to cluster member1 and member2 by using pp (PropagationPolicy).
When cluster member1 fails, if it is a replica split strategy, the Pods on cluster member1 will be cleared and migrated to cluster member2 that meets the requirements. If it is a full-volume strategy, the deployment on cluster member1 will be removed and migrated to cluster member3 that meets the requirements.
Karmada implements failover, which is mainly completed by the six controllers in karmada-controller-manager and karmada-scheduler.
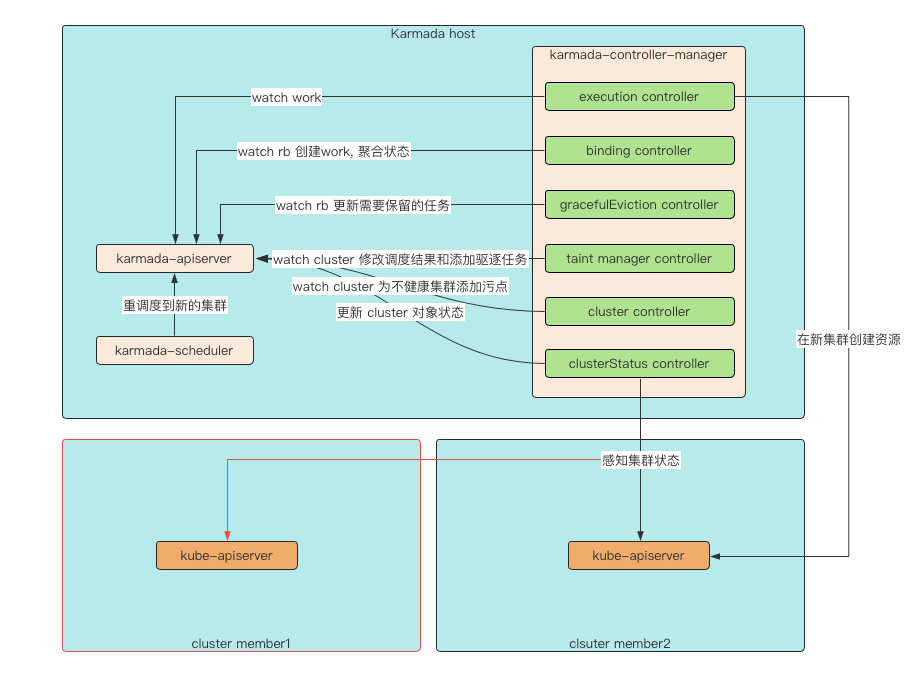
- clusterStatus controller: Perceives the cluster status and writes the cluster status to the status of the cluster resource object on the control plane.
- cluster controller: Create an execution namespace on the control plane (the execution namespace here refers to Karmada A namespace with special naming rules will be created for each member cluster on the control plane, which is used to store work ), and it is judged according to conditions whether the cluster needs to be stained.
- taint-manager controller: According to the cluster taint, the cluster taint tolerated in the propagation strategy is compared and calculated to determine whether to expel the resources on the cluster.
- Karmada-scheduler: According to the propagation strategy and cluster conditions, select the best scheduling cluster for resources.
- GracefulEviction controller: After ensuring that the resource status on the new cluster is healthy, remove the resource objects on the eviction cluster.
- Binding controller: According to the scheduling result, apply the rules in the propagation strategy, and create a work under the execution namespace corresponding to the control plane cluster. Aggregate work status, update rb(ResourceBinding) and resource template status.
- Execution controller: Create resources in the member cluster according to the work under the corresponding execution namespace of the member cluster.
Next, let's take a look at the capabilities of each controller and scheduler in the cluster failure recovery scenario.
clusterStatus controller¶
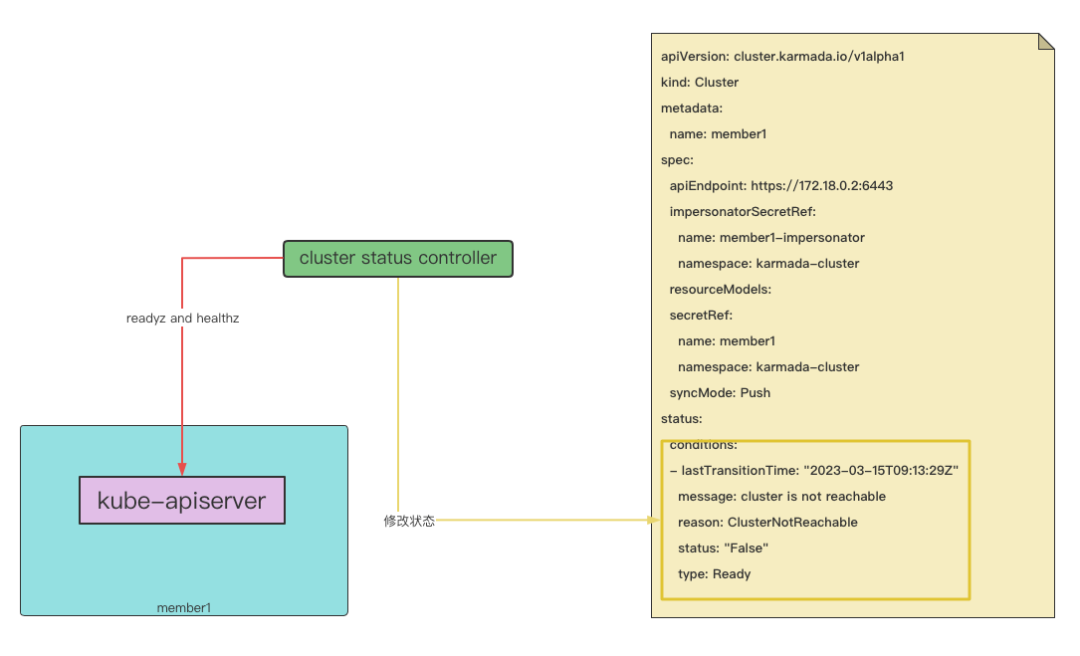
The clusterStatus controller is mainly used to synchronize the actual status of the cluster. clusterStatus controller when the cluster is unreachable It will perceive that the cluster status is offline, and then update the status of the cluster resource object on the control plane, and modify the The condition status of type is Ready is 'False', the following is the main implementation code.
First, get the online status and health status of the member cluster by accessing '/readyz' and '/healthz' of the member cluster kube-apiserver.
func getClusterHealthStatus(clusterClient *util.ClusterClient) (online, healthy bool) {
healthStatus, err := healthEndpointCheck(clusterClient. KubeClient, "/readyz")
if err != nil && healthStatus == http.StatusNotFound {
// do health check with healthz endpoint if the readyz endpoint is not installed in member cluster
healthStatus, err = healthEndpointCheck(clusterClient. KubeClient, "/healthz")
}
if err != nil {
klog.Errorf("Failed to do cluster health check for cluster %v, err is : %v ", clusterClient.ClusterName, err)
return false, false
}
if healthStatus != http.StatusOK {
klog.Infof("Member cluster %v isn't healthy", clusterClient.ClusterName)
return true, false
}
return true, true
}
Second, initialize conditions based on online status and health status.
func generateReadyCondition(imagesalthy bool) metav1. Condition {
if !online {
return util.NewCondition(clusterv1alpha1.ClusterConditionReady, clusterNotReachableReason, clusterNotReachableMsg, metav1.ConditionFalse)
}
if !healthy {
return util.NewCondition(clusterv1alpha1.ClusterConditionReady, clusterNotReady, clusterUnhealthy, metav1.ConditionFalse)
}
return util.NewCondition(clusterv1alpha1.ClusterConditionReady, clusterReady, clusterHealthy, metav1.ConditionTrue)
}
Finally, if the cluster has been offline and the initialized condition status is not 'True', Then it is considered that the conditions of the cluster resource object need to be updated. The status of the condition whose type is Ready in conditions will be changed to 'False' and then returned.
online, healthy := getClusterHealthStatus(clusterClient)
observedReadyCondition := generateReadyCondition(online, healthy)
readyCondition := c.clusterConditionCache.thresholdAdjustedReadyCondition(cluster, &observedReadyCondition)
// cluster is offline after retry timeout, update cluster status immediately and return.
if !online && readyCondition.Status != metav1.ConditionTrue {
klog.V(2).Infof("Cluster(%s) still offline after %s, ensuring offline is set.",
cluster.Name, c.ClusterFailureThreshold.Duration)
setTransitionTime(cluster. Status. Conditions, readyCondition)
meta.SetStatusCondition(¤tClusterStatus.Conditions, *readyCondition)
return c. updateStatusIfNeeded(cluster, currentClusterStatus)
}
cluster controller¶
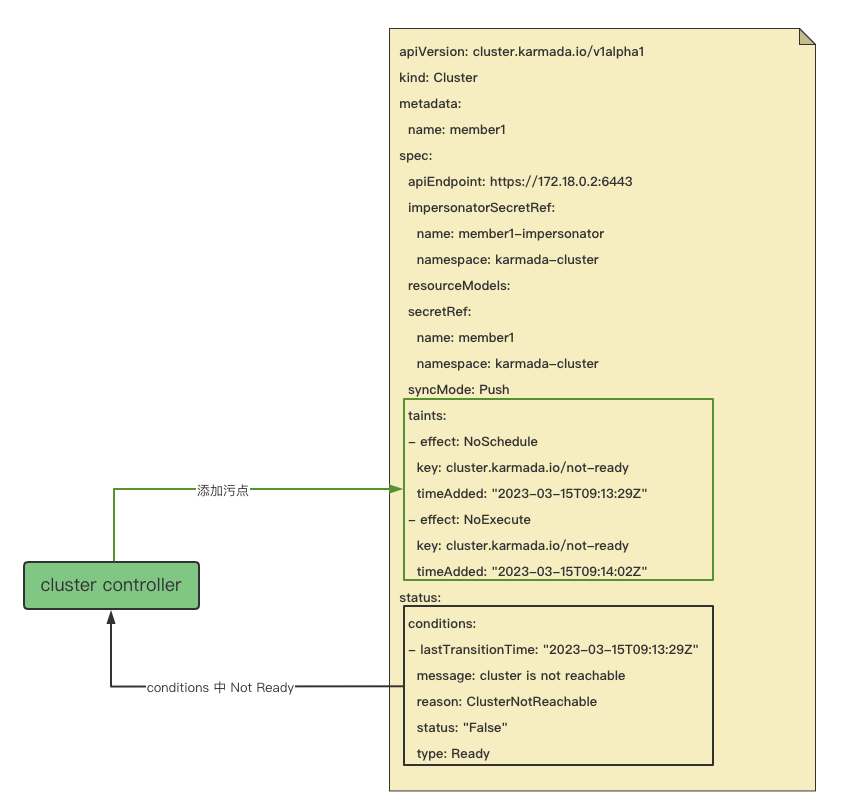
The cluster controller will judge whether it is necessary to mark the cluster as unschedulable and unexecutable according to the conditions in the current state of the cluster. The following code implements the logic for the core. When the status of the condition whose type is Ready in the conditions is 'False', Run the UpdateClusterControllerTaint function to add effects as NoSchedule and NoExecute taints.
func (c *Controller) taintClusterByCondition(ctx context.Context, cluster *clusterv1alpha1.Cluster) error {
currentReadyCondition := meta.FindStatusCondition(cluster.Status.Conditions, clusterv1alpha1.ClusterConditionReady)
var err error
if currentReadyCondition != nil {
switch currentReadyCondition.Status {
case metav1.ConditionFalse:
// Add NotReadyTaintTemplateForSched taint immediately.
if err = utilhelper.UpdateClusterControllerTaint(ctx, c.Client, []*corev1.Taint{NotReadyTaintTemplateForSched}, []*corev1.Taint{UnreachableTaintTemplateForSched}, cluster); err != nil {
klog.ErrorS(err, "Failed to instantly update UnreachableTaintForSched to NotReadyTaintForSched, will try again in the next cycle.", "cluster", cluster.Name)
}
case metav1.ConditionUnknown:
// Add UnreachableTaintTemplateForSched taint immediately.
if err = utilhelper.UpdateClusterControllerTaint(ctx, c.Client, []*corev1.Taint{UnreachableTaintTemplateForSched}, []*corev1.Taint{NotReadyTaintTemplateForSched}, cluster); err != nil {
klog.ErrorS(err, "Failed to instantly swap NotReadyTaintForSched to UnreachableTaintForSched, will try again in the next cycle.", "cluster", cluster.Name)
}
case metav1.ConditionTrue:
if err = utilhelper.UpdateClusterControllerTaint(ctx, c.Client, nil, []*corev1.Taint{NotReadyTaintTemplateForSched, UnreachableTaintTemplateForSched}, cluster); err != nil {
klog.ErrorS(err, "Failed to remove schedule taints from cluster, will retry in next iteration.", "cluster", cluster.Name)
}
}
} else {
// Add NotReadyTaintTemplateForSched taint immediately.
if err = utilhelper.UpdateClusterControllerTaint(ctx, c.Client, []*corev1.Taint{NotReadyTaintTemplateForSched}, nil, cluster); err != nil {
klog.ErrorS(err, "Failed to add a NotReady taint to the newly added cluster, will try again in the next cycle.", "cluster", cluster.Name)
}
}
return err
}
taint-manager controller¶
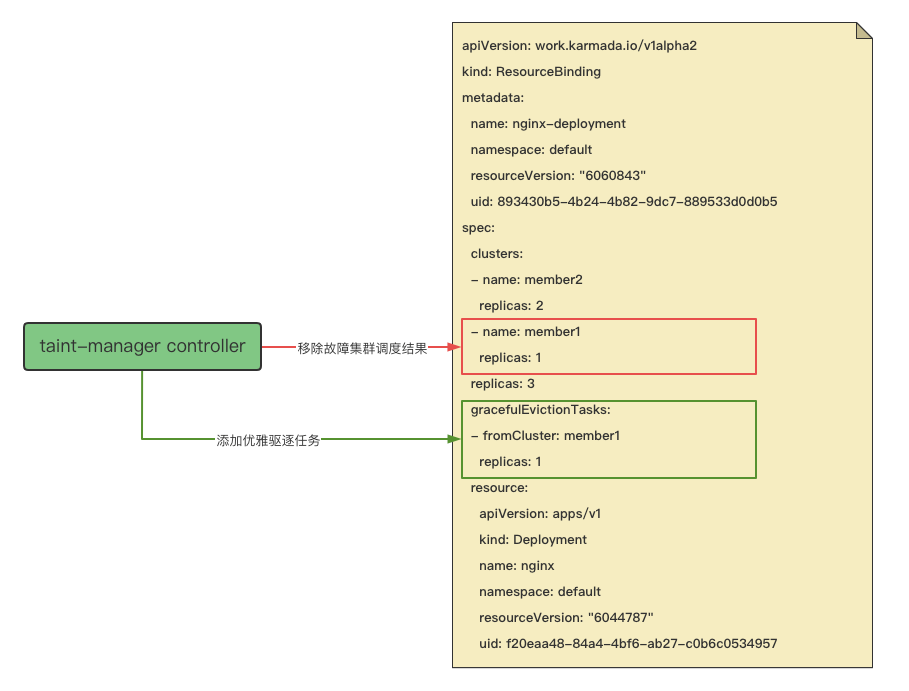
The taint-manager controller starts synchronously with the cluster controller, and can be configured with parameters to decide whether to start or not (default is to start). It detects changes in resource objects of the cluster, and when it detects a taint on the cluster with an effect of NoExecute, it will retrieve all namespace-level and cluster-level ResourceBindings (rb) on that cluster and put them into the corresponding eviction processing queue. The eviction processing worker will check the PropagationPolicy (pp) of the rb it retrieved to see if there is a cluster taint tolerance. If there is a match, it will skip and consider the resources on that cluster as not needing eviction. Otherwise, it will need to evict the resources. If eviction is necessary, it will then check if graceful eviction is enabled (which is enabled by default), and add a new graceful eviction task for the rb object, meaning adding a new graceful eviction task to rb.spec.gracefulEvictionTasks.
needEviction, tolerationTime, err := tc.needEviction(cluster, binding.Annotations)
if err != nil {
klog.ErrorS(err, "Failed to check if binding needs eviction", "binding", fedKey.ClusterWideKey.NamespaceKey())
return err
}
// Case 1: Need eviction now.
// Case 2: Need eviction after toleration time. If time is up, do eviction right now.
// Case 3: Tolerate forever, we do nothing.
if needEviction || tolerationTime == 0 {
// update final result to evict the target cluster
if features.FeatureGate.Enabled(features.GracefulEviction) {
binding.Spec.GracefulEvictCluster(cluster, workv1alpha2.EvictionProducerTaintManager, workv1alpha2.EvictionReasonTaintUntolerated, "")
} else {
binding.Spec.RemoveCluster(cluster)
}
if err = tc.Update(context.TODO(), binding); err != nil {
helper.EmitClusterEvictionEventForResourceBinding(binding, cluster, tc.EventRecorder, err)
klog.ErrorS(err, "Failed to update binding", "binding", klog.KObj(binding))
return err
}
if !features.FeatureGate.Enabled(features.GracefulEviction) {
helper.EmitClusterEvictionEventForResourceBinding(binding, cluster, tc.EventRecorder, nil)
}
} else if tolerationTime > 0 {
tc.bindingEvictionWorker.AddAfter(fedKey, tolerationTime)
}
It can be noticed that when writing an eviction task, the cluster corresponding to the graceful eviction task will be removed from rb.spec.clusters , which means that the scheduling result will be modified. (Here it needs to be emphasized that the scheduling result is the scheduling and distribution cluster selected by Karmada scheduler based on the propagation strategy and cluster situation for resources, and the scheduling result will be recorded in the spec.clusters attribute of rb (ResourceBinding).) This means that due to cluster failures, the scheduler will be triggered to reschedule, and resources should be evicted from the failed cluster and created on the new cluster.
// This feature no-(images cluster does not exist.
func (s *ResourceBindingSpec) GracefulEvictCluster(name, producer, reason, message string) {
// find the cluster index
var i int
for i = 0; i < len(s.Clusters); i++ {
if s.Clusters[i].Name == name {
break
}
}
// not found, do nothing
if i >= len(s.Clusters) {
return
}
// build eviction task
evictingCluster := s.Clusters[i].DeepCopy()
evictionTask := GracefulEvictionTask{
FromCluster: evictingCluster.Name,
Reason: reason,
Message: message,
Producer: producer,
}
if evictingCluster.Replicas > 0 {
evictionTask.Replicas = &evictingCluster.Replicas
}
s.GracefulEvictionTasks = append(s.GracefulEvictionTasks, evictionTask)
s.Clusters = append(s.Clusters[:i], s.Clusters[i+1:]...)
}
Karmada scheduler¶
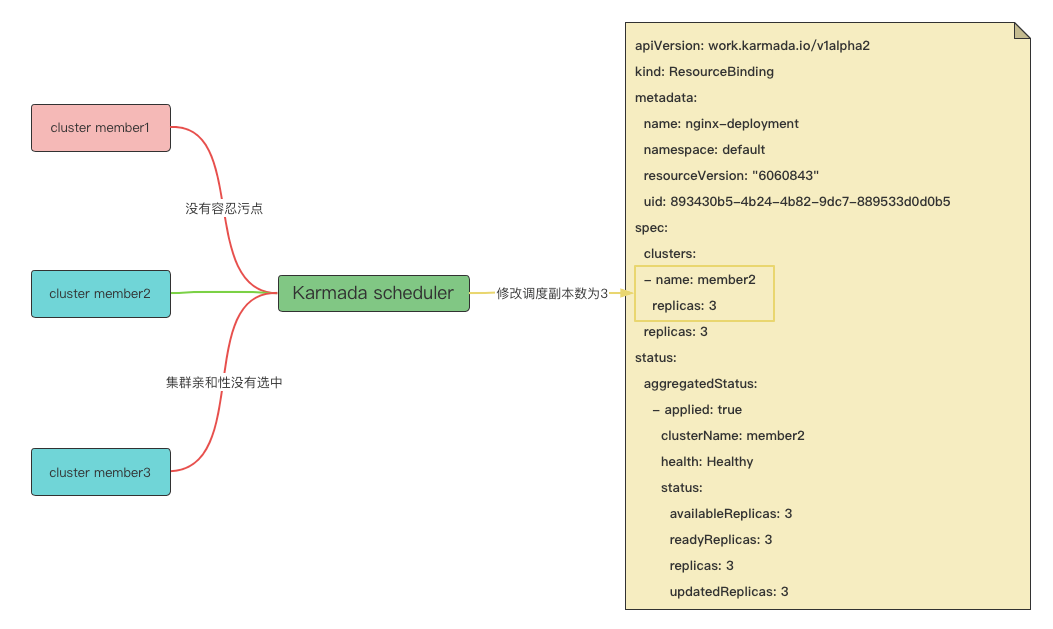
Karmada scheduler, if the scheduled target copy is not equal to the expected target copy, that is, when the sum of all copies under rb.spec.clusters (resource scheduling cluster result) is not equal to rb.spec.replicas (resource expected copy), the scheduler considers this a capacity expansion or contraction operation, thus triggering a rescheduling operation. Whereas in taint-manager controller, resources are evicted from the failed cluster due to cluster failure, taint-manager controller Modified the scheduling results, removed a cluster under rb.spec.clusters, resulting in rb.spec.clusters The sum of all replicas below is less than rb.spec.replicas, so this is an expansion operation.
The judgment of whether rescheduling is needed here, the core logic is ‘replicasSum != bindingSpec.Replicas’. The scheduling result of cluster member1 in the scheduling result is removed, so the value of replicasSum is 2 at this time, But bindingSpec.Replicas has a value of 3, which is not equal so the function returns true.
// IsBindingReplicasChanged will check if the sum of replicas is different from the replicas of object
func IsBindingReplicasChanged(bindingSpec *workv1alpha2.ResourceBindingSpec, strategy *policyv1alpha1.ReplicaSchedulingStrategy) bool {
if strategy == nil {
return false
}
if strategy.ReplicaSchedulingType == policyv1alpha1.ReplicaSchedulingTypeDuplicated {
for _, targetCluster := range bindingSpec. Clusters {
if targetCluster.Replicas != bindingSpec.Replicas {
return true
}
}
return false
}
if strategy.ReplicaSchedulingType == policyv1alpha1.ReplicaSchedulingTypeDivided {
replicasSum := GetSumOfReplicas(bindingSpec. Clusters)
return replicasSum != bindingSpec.Replicas
}
return false
}
Since the function IsBindingReplicasChanged returns true and ReplicaScheduling is set, the rescheduling operation will be performed.
if rb.Spec.Placement.ReplicaScheduling != nil && util.IsBindingReplicasChanged(&rb.Spec, rb.Spec.Placement.ReplicaScheduling) {
// binding replicas changed, need reschedule
klog.Infof("Reschedule ResourceBinding(%s/%s) as replicas scaled down or scaled up", namespace, name)
err = s.scheduleResourceBinding(rb)
metrics.BindingSchedule(string(ScaleSchedule), utilmetrics.DurationInSeconds(start), err)
return err
}
In the rescheduling logic, because the cluster member1 is tainted, it will be filtered out by the scheduling plug-in, and the cluster member3 is not selected by the cluster affinity. As a result, only member2 satisfies the requirement.
// Filter checks if the given tolerations in placement tolerate cluster's taints.
func (p *TaintToleration) Filter(
_context.Context,
bindingSpec *workv1alpha2.ResourceBindingSpec,
_ *workv1alpha2.ResourceBindingStatus,
cluster *clusterv1alpha1.Cluster,
) *framework. Result {
// skip the filter if the cluster is already in the list of scheduling results,
// if the workload referencing by the binding can't tolerate the taint,
// the taint-manager will evict it after a graceful period.
if bindingSpec.TargetContains(cluster.Name) {
return framework. NewResult(framework. Success)
}
filterPredicate := func(t *corev1. Taint) bool {
return t.Effect == corev1.TaintEffectNoSchedule || t.Effect == corev1.TaintEffectNoExecute
}
taint, isUntolerated := v1helper.FindMatchingUntoleratedTaint(cluster.Spec.Taints, bindingSpec.Placement.ClusterTolerations, filterPredicate)
if !isUntolerated {
return framework. NewResult(framework. Success)
}
return framework.NewResult(framework.Unschedulable, fmt.Sprintf("cluster(s) had untolerated taint {%s}", taint.ToString()))
}
When calculating the scheduling copy, since the static weight is set, it is necessary to use the static weight method (The static weight method means that the replicas are split according to the ratio set by the administrator. For example, if the total number of replicas is expected to be 9, The static weight of cluster member1 is 1, and the static weight of cluster member2 is 2, then the replica calculation method on cluster member1 is 9*⅓=3, The replica calculation method on cluster member2 is 9*⅔=6) for replica splitting. However, since only one cluster meets the requirements, Therefore, when setting the cluster scheduling replica, the replica scheduling result of cluster member2 is 3, so the scheduler will set rb.spec.clusters (Resource Scheduling Cluster Result) The replica scheduling result on cluster member2 is changed from 2 to 3.
// TakeByWeight divide replicas by a weight list and merge the result into previous result.
func (a *Dispenser) TakeByWeight(w ClusterWeightInfoList) {
if a. Done() {
return
}
sum := w. GetWeightSum()
if sum == 0 {
return
}
sort. Sort(w)
result := make([]workv1alpha2.TargetCluster, 0, w.Len())
remain := a.NumReplicas
for _, info := range w {
replicas := int32(info. Weight * int64(a. NumReplicas) / sum)
result = append(result, workv1alpha2.TargetCluster{
Name: info. ClusterName,
Replicas: replicas,
})
remain -= replicas
}
// TODO(Garrybest): take rest replicas by fraction part
for i := range result {
if remain == 0 {(image(images
break
}
result[i].Replicas++
remain--
}
a.NumReplicas = remain
a.Result = util.MergeTargetClusters(a.Result, result)
}
The following is a partial log of the scheduler during fault recovery, and you can clearly see the process of the entire cluster screening and replica calculation. Cluster member1 is filtered out because it does not tolerate taint, and cluster member3 is filtered out because it is not selected by cluster affinity. The final scheduling result is cluster member2, and the scheduling copy is 3.
I0217 06:46:53.057843 1 scheduler.go:390] Reschedule ResourceBinding(default/nginx-deployment) as replicas scaled down or scaled up
I0217 06:46:53.057888 1 scheduler.go:473] "Begin scheduling resource binding" resourceBinding="default/nginx-deployment"
I0217 06:46:53.083460 1 generic_scheduler.go:119] cluster "member3" is not fit, reason: cluster(s) didn't match the placement cluster affinity constraint
I0217 06:46:53.083524 1 generic_scheduler.go:119] cluster "member1" is not fit, reason: cluster(s) had untolerated taint {cluster.karmada.io/not-ready: }
I0217 06:46:53.083542 1 generic_scheduler.go:73] feasible clusters found: [member2]
I0217 06:46:53.083567 1 generic_scheduler.go:146] Plugin ClusterLocality scores on default/nginx => [{member2 100}]
I0217 06:46:53.083590 1 generic_scheduler.go:146] Plugin ClusterAffinity scores on default/nginx => [{member2 0}]
I0217 06:46:53.083601 1 generic_scheduler.go:79] feasible clusters scores: [{member2 100}]
I0217 06:46:53.085488 1 util.go:72] Target cluster: [{member2 99}]
I0217 06:46:53.085532 1 select_clusters.go:19] select all clusters
I0217 06:46:53.085548 1 generic_scheduler.go:85] selected clusters: [member2]
I0217 06:46:53.085571 1 scheduler.go:489] ResourceBinding default/nginx-deployment scheduled to clusters [{member2 3}]
I0217 06:46:53.151403 1 scheduler.go:491] "End scheduling resource binding" resourceBinding="default/nginx-deployment"
gracefulEviction controller¶
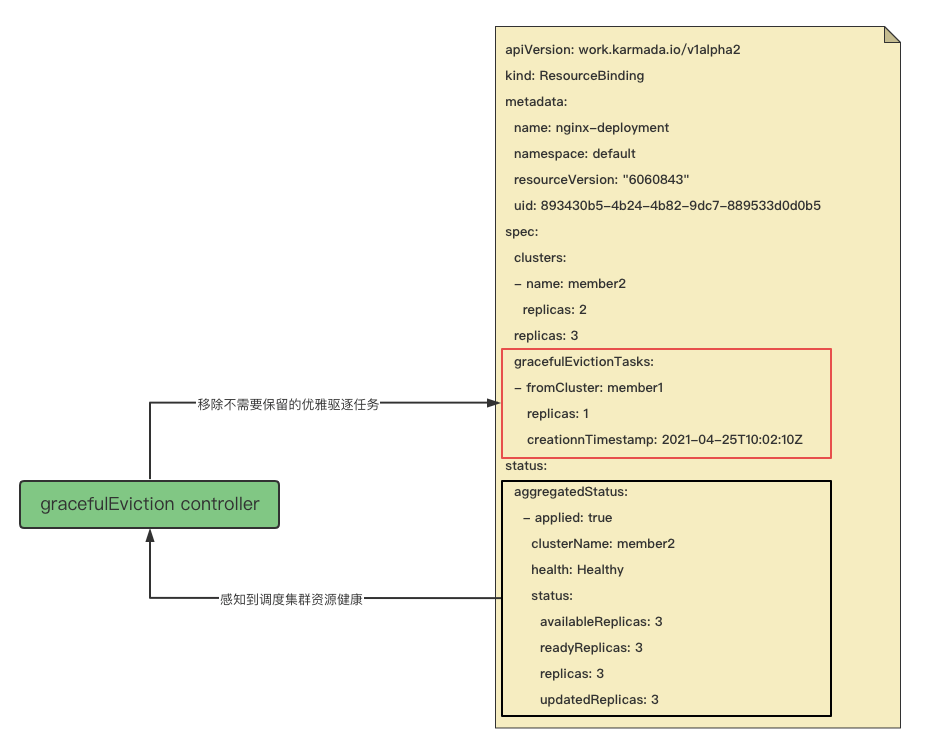
The gracefulEviction controller senses changes to rb(ResourceBinding) resources with rb.spec.gracefulEvictionTasks, That is, only care about rb (ResourceBinding) that needs graceful eviction. Then according to the scheduling target cluster, obtain the resource health status of the scheduling result cluster, If all the resources of the scheduling target cluster are healthy, it is considered unnecessary to keep the graceful eviction task, so the eviction cluster task is removed, that is, the cluster member1 The Graceful Eviction quest on was removed. From this, we can find that the logic of elegant eviction is to ensure that after the new replica is ready on the cluster that meets the requirements, Then remove the graceful eviction task, that is, delete the old resources scheduled to the faulty cluster.
// assessEvictionTasks assesses each task according to graceful eviction rules and
// returns the tasks that should be kept.
func assessEvictionTasks(bindingSpec workv1alpha2.ResourceBindingSpec,
obse(images[]workv1alpha2.AggregatedStatusItem,
timeout time.Duration,
now metav1.Time,
) ([]workv1alpha2.GracefulEvictionTask, []string) {
var keptTasks []workv1alpha2.GracefulEvictionTask
var evictedClusters []string
for _, task := range bindingSpec.GracefulEvictionTasks {
// set creation timestamp for new task
if task.CreationTimestamp.IsZero() {
task.CreationTimestamp = now
keptTasks = append(keptTasks, task)
continue
}
// assess task according to observed status
kt := assessSingleTask(task, assessmentOption{
scheduleResult: bindingSpec.Clusters,
timeout: timeout,
observedStatus: observedStatus,
})
if kt != nil {
keptTasks = append(keptTasks, *kt)
} else {
evictedClusters = append(evictedClusters, task.FromCluster)
}
}
return keptTasks, evictedClusters
}
binding controller¶
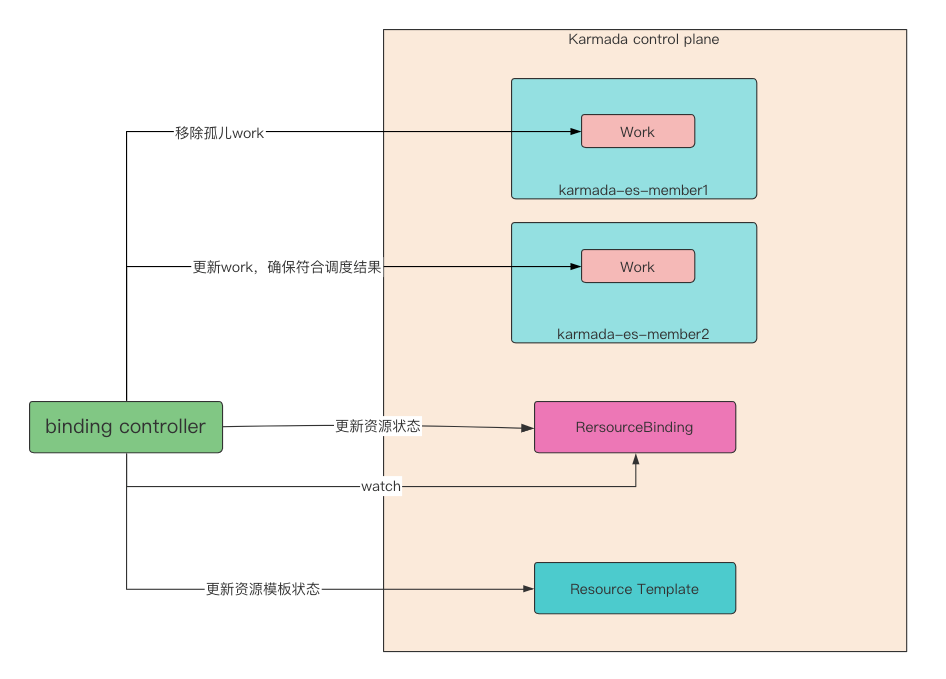
When the rb (ResourceBinding) resource changes, it will be sensed by the binding controller. First, the orphan work will be removed (work is used to store the resource object templates that need to be actually created on the member clusters after the propagation policy rules are passed. Orphan work refers to the resource corresponding to rb (ReesourceBinding), but with the change of rb, the work is no longer the work expected by rb). Except for the clusters contained in the three attributes in rb(ResourceBinding), the work under the execution namespace corresponding to other clusters will be considered as orphan work: The first is rb.spec.clusters, the resource scheduling cluster result; the second is rb.spec.requiredBy, depending on the resource list cluster of the application; The third is rb.spec.gracefulEvictionTasks, which gracefully evicts clusters in tasks. In the gracefulEviction controller, We know that tasks cannot be deleted until the newly scheduled cluster resources are ready. It's ingenious here, This ensures that the failed cluster work will never be removed until the newly started replica is Ready on the eligible cluster.
In the example, it can be found that after the failover occurs, work still exists under the corresponding execution namespace of the faulty cluster. In theory, The work in the faulty cluster has been judged as an orphan, so why is it not deleted successfully? Further exploration will find that the cluster member1 The DeletionTimestamp of the work under the namespace is not empty. The reason for not deleting is that there is a finalizer in work, The finalizer is added when the binding controller creates work. The reason why work cannot be removed directly here is, It is necessary to ensure that the resources on the member clusters are removed before the work can be removed. Otherwise, removing the work directly will cause the cluster member1 to recover, The resources on the cluster member1 are reserved, resulting in residual resources. Therefore, you need to wait for the faulty cluster to recover, and the execution controller The finalizer can only be removed after the resource corresponding to the work on the member cluster is successfully removed, so that the work will be deleted.
...
apiVersion: work.karmada.io/v1alpha1
kind: Work
metadata:
annotations:
resourcebinding.karmada.io/name: nginx-deployment
resourcebinding.karmada.io/namespace: default
creationTimestamp: "2023-02-17T08:53:08Z"
deletionGracePeriodSeconds: 0
deletionTimestamp: "2023-02-17T08:55:39Z"
finalizers:
- karmada.io/execution-controller
generation: 2
labels:
resourcebinding.karmada.io/key: 687f7fb96f
name: nginx-687f7fb96f
namespace: karmada-es-member1
resourceVersion: "28134"
uid: d215a03c-522d-4a89-9c5d-e87e27338a03
...
The following is the core code of the binding controller, and its core logic is:
- Remove orphaned work;
- Ensure that the expected work of rb (ResourceBinding) meets expectations;
- Aggregate the status of the work and record it in the state of rb (ResourceBinding);
- Based on the aggregated state of rb (ResourceBinding), update the status of the resource template. The resource template refers to the object of the resource template stored on the Karmada control plane.
// syncBinding will sync resourceBinding to Works.
func (c *ResourceBindingController) syncBinding(binding *workv1alpha2.ResourceBinding) (controllerruntime.Result, error) {
if err := c.removeOrphanWorks(binding); err != nil {
return controllerruntime.Result{Requeue: true}, err
}
workload, err := helper.FetchWorkload(c.DynamicClient, c.InformerManager, c.RESTMapper, binding.Spec.Resource)
if err != nil {
if apierrors.IsNotFound(err) {// It might happen when the resource template has been removed but the garbage collector hasn't removed
// the ResourceBinding which dependent on resource template.
// So, just return without retry(requeue) would save unnecessary loop.
return controllerruntime.Result{}, nil
}
klog.Errorf("Failed to fetch workload for resourceBinding(%s/%s). Error: %v.",
binding.GetNamespace(), binding.GetName(), err)
return controllerruntime.Result{Requeue: true}, err
}
var errs []error
start := time.Now()
err = ensureWork(c.(imagesesourceInterpreter, workload, c.OverrideManager, binding, apiextensionsv1.NamespaceScoped)
metrics.ObserveSyncWorkLatency(binding.ObjectMeta, err, start)
if err != nil {
klog.Errorf("Failed to transform resourceBinding(%s/%s) to works. Error: %v.",
binding.GetNamespace(), binding.GetName(), err)
c.EventRecorder.Event(binding, corev1.EventTypeWarning, events.EventReasonSyncWorkFailed, err.Error())
c.EventRecorder.Event(workload, corev1.EventTypeWarning, events.EventReasonSyncWorkFailed, err.Error())
errs = append(errs, err)
} else {
msg := fmt.Sprintf("Sync work of resourceBinding(%s/%s) successful.", binding.Namespace, binding.Name)
klog.V(4).Infof(msg)
c.EventRecorder.Event(binding, corev1.EventTypeNormal, events.EventReasonSyncWorkSucceed, msg)
c.EventRecorder.Event(workload, corev1.EventTypeNormal, events.EventReasonSyncWorkSucceed, msg)
}
if err = helper.AggregateResourceBindingWorkStatus(c.Client, binding, workload, c.EventRecorder); err != nil {
klog.Errorf("Failed to aggregate workStatuses to resourceBinding(%s/%s). Error: %v.",
binding.GetNamespace(), binding.GetName(), err)
errs = append(errs, err)
}
if len(errs) > 0 {
return controllerruntime.Result{Requeue: true}, errors.NewAggregate(errs)
}
err = c.updateResourceStatus(binding)
if err != nil {
return controllerruntime.Result{Requeue: true}, err
}
return controllerruntime.Result{}, nil
}
execution controller¶
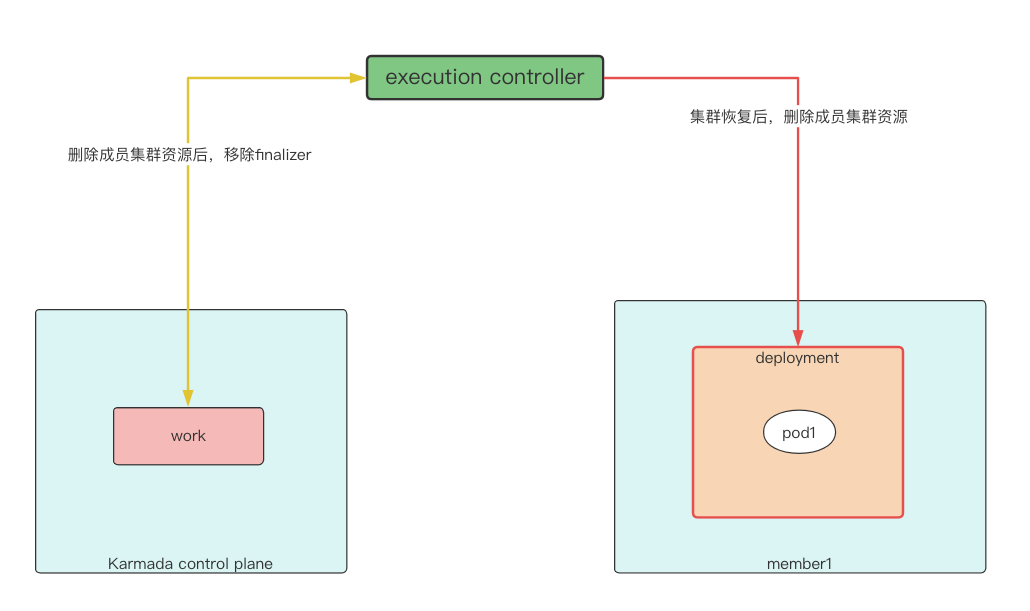
The ability of the execution controller is to create, update, or delete the resources that actually need to be delivered stored in the work of the corresponding execution namespace of the member cluster in the corresponding member cluster. Therefore, its execution logic is closely related to the state of the work and the state of the cluster. If the DeletionTimestamp of the work is not empty, that is, the work has been deleted, It will continue to judge the cluster status. If the cluster status is Ready, it will try to delete the resources on the member cluster. In the example, when the cluster fails, resources are transferred to the cluster member2 All replicas on the server are Ready, and the gracefulEviction controller will remove the cluster member1 graceful eviction task, the binding controller thinks The work on member1 is orphaned, so the work will be deleted. At this time, the work DeletionTimestamp under the cluster member1 execution namespace is not empty, At the same time, the cluster is Not Ready, so it will enter the judgment branch of cluster.DeletionTimestamp.IsZero() to re-enter the queue, work finalizer will not be removed, so work always exists in the example. When the cluster recovers, it will enter the util.IsClusterReady(&cluster.Status) branch, At this time, it will try to delete the resource corresponding to the work on the member cluster. After the deletion is successful, run removeFinalizer to remove the finalizer on the work. The work will then be deleted. Therefore, after the cluster recovery in the example, the work under the cluster member1 execution namespace and the deployment on the member cluster are removed.
if !work.DeletionTimestamp.IsZero() {
// Abort deleting workload if cluster is unready when unjoining cluster, otherwise the unjoin process will be failed.
if util.IsClusterReady(&cluster.Status) {
err := c.tryDeleteWorkload(clusterName, work)
if err != nil {
klog.Errorf("Failed to delete work %v, namespace is %v, err is %v", work.Name, work.Namespace, err)
return controllerruntime.Result{Requeue: true}, err
}
} else if cluster.DeletionTimestamp.IsZero() { // cluster is unready, but not terminating
return controllerruntime.Result{Requeue: true}, fmt.Errorf("cluster(%s) not ready", cluster.Name)
}
return c.removeFinalizer(work)
}
The above is the principle of Karmada's implementation of fault recovery. It can be seen from it that it is completed by the cooperation of multiple controllers and schedulers. If one of the controllers or the scheduler fails, it will affect the failover functionality. The author once mentioned an issue 2769 where the failover did not meet expectations. It was finally found that it was caused by a resource status calculation error. See pull request 2928 for detailed modifications. This is because during failover, Graceful eviction is enabled, and graceful eviction will obtain the health status of resources on the scheduling target cluster, and calculate whether they are all Healthy, and if they are all Healthy The graceful eviction task will be removed, but due to the status calculation error, the resources on the actually transferred target cluster are all Healthy, but the graceful eviction controller is calculated as Healthy, so the elegant eviction task has been kept, resulting in a problem in the issue. As another example in issue 2989, it is mentioned that the work status is still Healthy, this is because the member cluster status is Not Ready, which causes the execution controller to re-queue before updating the work status, So the state of work is still correct, but the DeletionTimestamp of work is not empty at this time.
Summarize¶
The current version of Karmada can implement the replica split strategy and the full strategy, but in real business cases, for example, how to implement failover for stateful applications? How to ensure the network and storage of the application after transfer? This needs to be further verified by actual operation, and needs to be analyzed in detail according to the actual situation.
At the same time, in the process of communicating with customers, some customers mentioned whether it is possible to reschedule and return the replica to the recovered cluster after the cluster failure is restored. At present, this is mentioned in the participating community meeting. The current direction of the community is that in the future, customers may be provided with the ability to choose whether to reschedule. In other words, future versions of Karmada may support user-defined whether to schedule back to the restored cluster. The reason why there is no scheduling back to the original cluster is because of the impact of rescheduling on application stability. At the same time, in the latest community meeting, there are discussions about enhancing the feature of Failover, which will add more configuration capabilities of Failover to the communication strategy, The specific discussion will not be launched here, we look forward to it together.
To sum up, **Karmada-based applications can achieve high availability at the cluster level. ** With the development of multiple clouds at any time, Karmada is used by more and more people. We believe that Karmada will solve practical problems in more and more use cases. Among the CNCF project contributions that the author participated in, Karmada is currently the project with the fastest response to issues and the fastest processing of code merge requests. This is due to the good code contribution management mechanism of the community leader. So, based on the growing usage of users, With the rapid response from the community, I believe that Karmada will bring us more and more amazing capabilities.
References¶
- Karmada source code
- Karmada official document
- Cloud native multicloud booster - Karmada overview
- Cloud native multicloud booster - Karmada controller
- Cloud native multicloud booster - Karmada scheduler