Elasticsearch 排障手册¶
本文将持续统计和梳理常见的 Elasticsearch 异常故障以及修复方式。若遇到使用问题,请优先查看此排障手册。
如果您发现遇到的问题未包含在本手册,可以快速跳转到页面底部,提交您的问题。
Elasticsearch PVC 磁盘容量满¶
存储依赖 hwameistor
报错信息¶
{"type": "server", "timestamp": "2022-12-18T10:47:08,573Z", "level": "ERROR", "component": "o.e.m.f.FsHealthService", "cluster.name": "mcamel-common-es-cluster-masters", "node.name": "mcamel-common-es-cluster-masters-es-masters-0", "message": "health check of [/usr/share/elasticsearch/data/nodes/0] failed", "cluster.uuid": "afIglgTVTXmYO2qPFNvsuA", "node.id": "nZRiBCUZQymQVV1son34pA" ,
"stacktrace": ["java.io.IOException: No space left on device",
"at sun.nio.ch.FileDispatcherImpl.write0(Native Method) ~[?:?]",
"at sun.nio.ch.FileDispatcherImpl.write(FileDispatcherImpl.java:62) ~[?:?]",
"at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:132) ~[?:?]",
"at sun.nio.ch.IOUtil.write(IOUtil.java:97) ~[?:?]",
"at sun.nio.ch.IOUtil.write(IOUtil.java:67) ~[?:?]",
"at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:285) ~[?:?]",
"at java.nio.channels.Channels.writeFullyImpl(Channels.java:74) ~[?:?]",
"at java.nio.channels.Channels.writeFully(Channels.java:96) ~[?:?]",
"at java.nio.channels.Channels$1.write(Channels.java:171) ~[?:?]",
"at java.io.OutputStream.write(OutputStream.java:127) ~[?:?]",
"at org.elasticsearch.monitor.fs.FsHealthService$FsHealthMonitor.monitorFSHealth(FsHealthService.java:170) [elasticsearch-7.16.3.jar:7.16.3]",
"at org.elasticsearch.monitor.fs.FsHealthService$FsHealthMonitor.run(FsHealthService.java:144) [elasticsearch-7.16.3.jar:7.16.3]",
"at org.elasticsearch.threadpool.Scheduler$ReschedulingRunnable.doRun(Scheduler.java:214) [elasticsearch-7.16.3.jar:7.16.3]",
"at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:777) [elasticsearch-7.16.3.jar:7.16.3]",
"at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:26) [elasticsearch-7.16.3.jar:7.16.3]",
"at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) [?:?]",
"at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) [?:?]",
"at java.lang.Thread.run(Thread.java:833) [?:?]"] }
解决方式¶
-
扩容 PVC(从 1Gi 修改为 10Gi)
-
PVC 扩容日志
查看 elasticsearch-data-mcamel-common-es-cluster-masters-es-masters-0 扩容日志信息。
kubectl describe pvc elasticsearch-data-mcamel-common-es-cluster-masters-es-masters-0 -n mcamel-systemName: elasticsearch-data-mcamel-common-es-cluster-masters-es-masters-0 Namespace: mcamel-system StorageClass: hwameistor-storage-lvm-hdd Status: Bound Volume: pvc-42309e19-b74f-45b4-9284-9c68b7dd93b3 Labels: common.k8s.elastic.co/type=elasticsearch elasticsearch.k8s.elastic.co/cluster-name=mcamel-common-es-cluster-masters elasticsearch.k8s.elastic.co/statefulset-name=mcamel-common-es-cluster-masters-es-masters Annotations: pv.kubernetes.io/bind-completed: yes pv.kubernetes.io/bound-by-controller: yes volume.beta.kubernetes.io/storage-provisioner: lvm.hwameistor.io volume.kubernetes.io/selected-node: xulongju-worker03 Finalizers: [kubernetes.io/pvc-protection] Capacity: 10Gi Access Modes: RWO VolumeMode: Filesystem Used By: mcamel-common-es-cluster-masters-es-masters-0 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal WaitForPodScheduled 51m (x18 over 55m) persistentvolume-controller waiting for pod mcamel-common-es-cluster-masters-es-masters-0 to be scheduled Normal WaitForFirstConsumer 50m (x7 over 56m) persistentvolume-controller waiting for first consumer to be created before binding Normal ExternalProvisioning 50m persistentvolume-controller waiting for a volume to be created, either by external provisioner "lvm.hwameistor.io" or manually created by system administrator Normal Provisioning 50m lvm.hwameistor.io_hwameistor-local-storage-csi-controller-68c9df8db8-kzdgn_680380b5-fc4d-4b82-ba80-5681e99a8711 External provisioner is provisioning volume for claim "mcamel-system/elasticsearch-data-mcamel-common-es-cluster-masters-es-masters-0" Normal ProvisioningSucceeded 50m lvm.hwameistor.io_hwameistor-local-storage-csi-controller-68c9df8db8-kzdgn_680380b5-fc4d-4b82-ba80-5681e99a8711 Successfully provisioned volume pvc-42309e19-b74f-45b4-9284-9c68b7dd93b3 Warning ExternalExpanding 3m39s volume_expand Ignoring the PVC: didn't find a plugin capable of expanding the volume; waiting for an external controller to process this PVC. Warning VolumeResizeFailed 3m39s external-resizer lvm.hwameistor.io resize volume "pvc-42309e19-b74f-45b4-9284-9c68b7dd93b3" by resizer "lvm.hwameistor.io" failed: rpc error: code = Unknown desc = volume expansion not completed yet Warning VolumeResizeFailed 3m39s external-resizer lvm.hwameistor.io resize volume "pvc-42309e19-b74f-45b4-9284-9c68b7dd93b3" by resizer "lvm.hwameistor.io" failed: rpc error: code = Unknown desc = volume expansion in progress Normal Resizing 3m38s (x3 over 3m39s) external-resizer lvm.hwameistor.io External resizer is resizing volume pvc-42309e19-b74f-45b4-9284-9c68b7dd93b3 Normal FileSystemResizeRequired 3m38s external-resizer lvm.hwameistor.io Require file system resize of volume on node Normal FileSystemResizeSuccessful 2m42s kubelet
Elasticsearch 业务索引别名被占用¶
现象:索引别名被占用
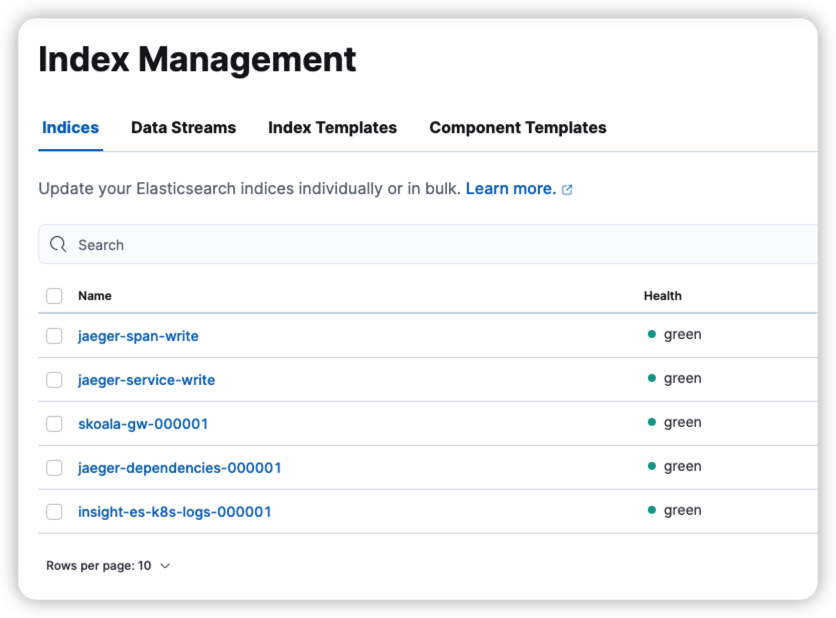
此图中 *-write 为别名,例如 jaeger-span-write ,需要对此别名进行处理
查看业务索引模板中使用的别名 rollover_alias 对应值
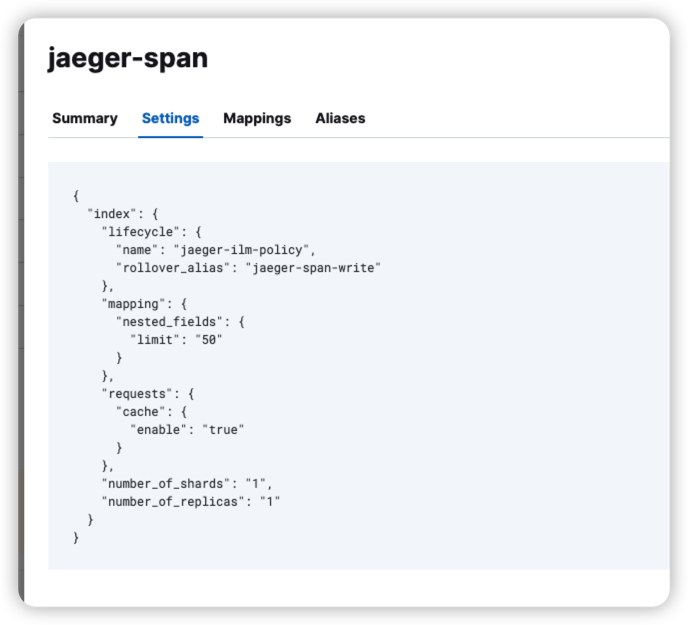
临时处理方式:进入 es pod 容器内执行以下脚本:
-
修改 TEMPLATE_NAME 对应值
-
修改 INDEX_ALIAS 对应值
-
需要进入 elasticsearch pod 中执行该脚本
-
修改里面 elastic 用户的密码值 (ES_PASSWORD=xxxx)
#!/bin/bash
# Add a template/policy/index
TEMPLATE_NAME=insight-es-k8s-logs
INDEX_ALIAS="${TEMPLATE_NAME}-alias"
ES_PASSWORD="DaoCloud"
ES_URL=https://localhost:9200
while [[ "$(curl -s -o /dev/null -w '%{http_code}\n' -u elastic:${ES_PASSWORD} $ES_URL -k)" != "200" ]]; do sleep 1; done
curl -XDELETE -u elastic:${ES_PASSWORD} -k "$ES_URL/${INDEX_ALIAS}"
curl -XPUT -u elastic:${ES_PASSWORD} -k "$ES_URL/${TEMPLATE_NAME}-000001" -H 'Content-Type: application/json' -d'{"aliases": {'\""${INDEX_ALIAS}"\"':{"is_write_index": true }}}'
注意:此脚本存在一定失败几率,取决于数据写入速度,作为临时解决方式。
真实情况需要停止数据源的写入情况,再执行上述方法。
报错 Error setting GoMAXPROCS for operator¶
报错信息
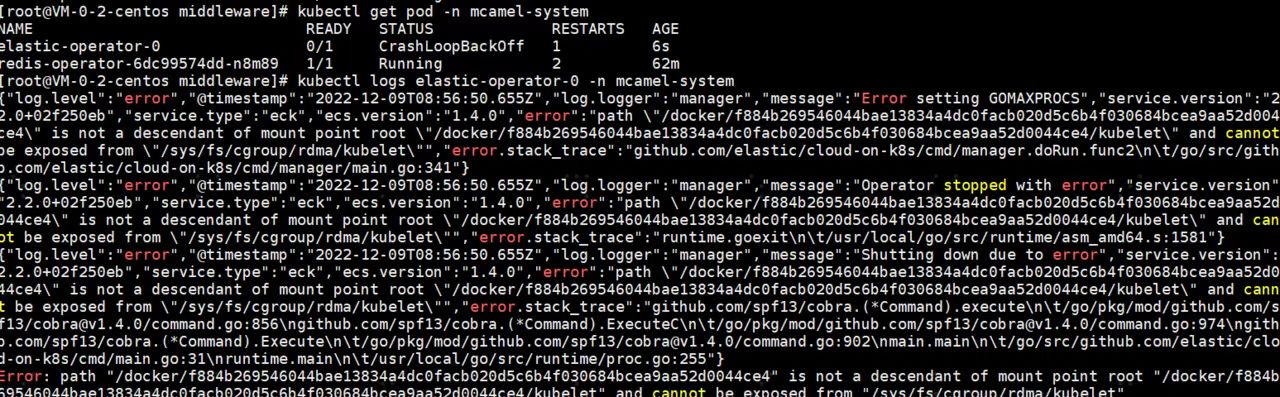
环境信息:
解决方式升级版本:
报错 Terminating due to java.lang.OutOfMemoryError: Java heap space¶
完整的报错信息如下:
{"type": "server", "timestamp": "2023-01-04T14:44:05,920Z", "level": "WARN", "component": "o.e.d.PeerFinder", "cluster.name": "gsc-cluster-1-master-es", "node.name": "gsc-cluster-1-master-es-es-data-0", "message": "address [127.0.0.1:9305], node [null], requesting [false] connection failed: [][127.0.0.1:9305] connect_exception: Connection refused: /127.0.0.1:9305: Connection refused", "cluster.uuid": "JOa0U_Q6T7WT60SPYiR1Ig", "node.id": "_zlorWVeRbyrUMYf9wJgfQ" }
{"type": "server", "timestamp": "2023-01-04T14:44:06,379Z", "level": "WARN", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "gsc-cluster-1-master-es", "node.name": "gsc-cluster-1-master-es-es-data-0", "message": "[gc][15375] overhead, spent [1.3s] collecting in the last [1.3s]", "cluster.uuid": "JOa0U_Q6T7WT60SPYiR1Ig", "node.id": "_zlorWVeRbyrUMYf9wJgfQ" }
{"timestamp": "2023-01-04T14:44:06+00:00", "message": "readiness probe failed", "curl_rc": "28"}
java.lang.OutOfMemoryError: Java heap space
Dumping heap to data/java_pid7.hprof ...
{"timestamp": "2023-01-04T14:44:11+00:00", "message": "readiness probe failed", "curl_rc": "28"}
{"timestamp": "2023-01-04T14:44:14+00:00", "message": "readiness probe failed", "curl_rc": "28"}
{"timestamp": "2023-01-04T14:44:17+00:00", "message": "readiness probe failed", "curl_rc": "28"}
{"timestamp": "2023-01-04T14:44:21+00:00", "message": "readiness probe failed", "curl_rc": "28"}
{"timestamp": "2023-01-04T14:44:26+00:00", "message": "readiness probe failed", "curl_rc": "28"}
{"timestamp": "2023-01-04T14:44:31+00:00", "message": "readiness probe failed", "curl_rc": "28"}
Heap dump file created [737115702 bytes in 25.240 secs]
Terminating due to java.lang.OutOfMemoryError: Java heap space
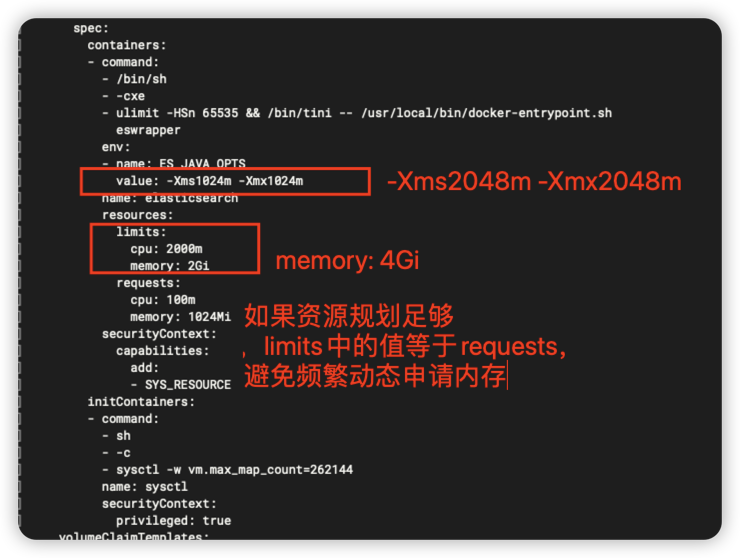
解决方式
如果在条件允许的情况下,可以进行资源及容量规划。
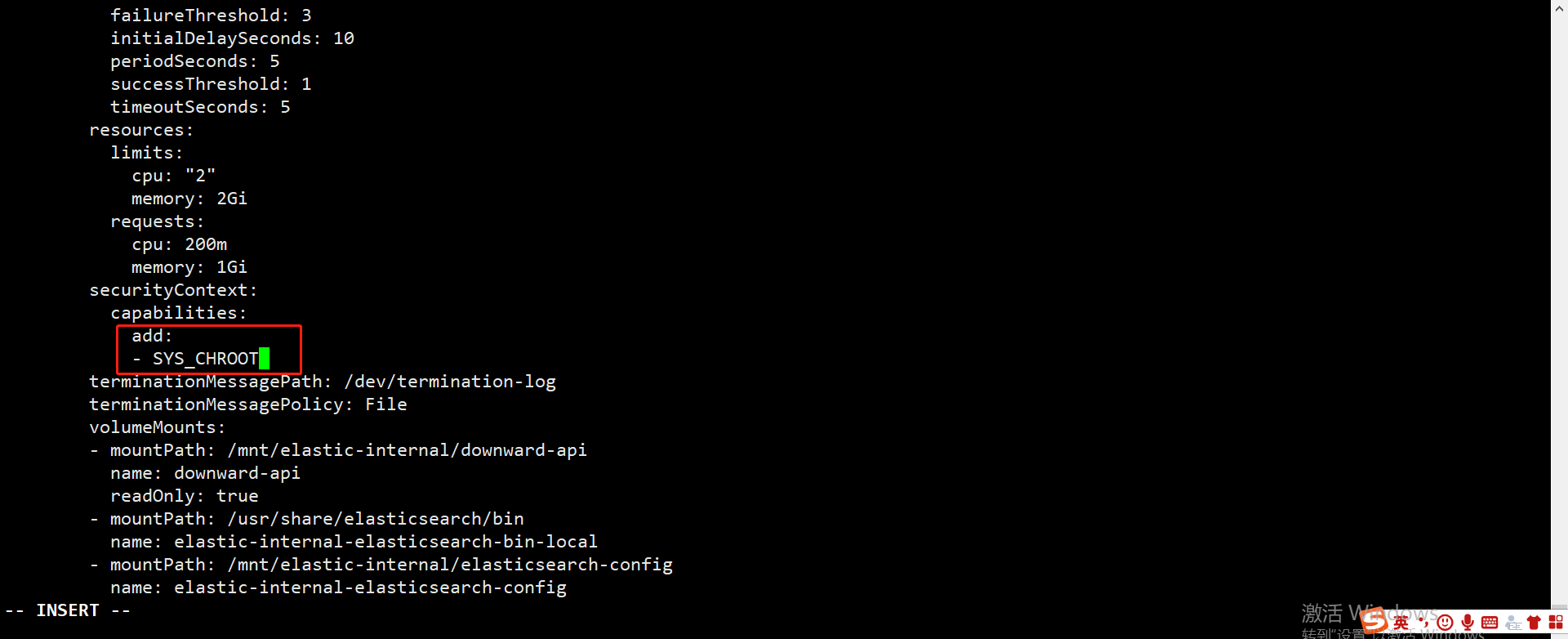
OCP 环境安装 Elasticsearch 时报错 Operation not permitted¶
报错信息

解决方式
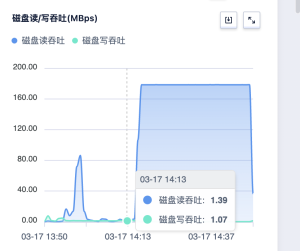
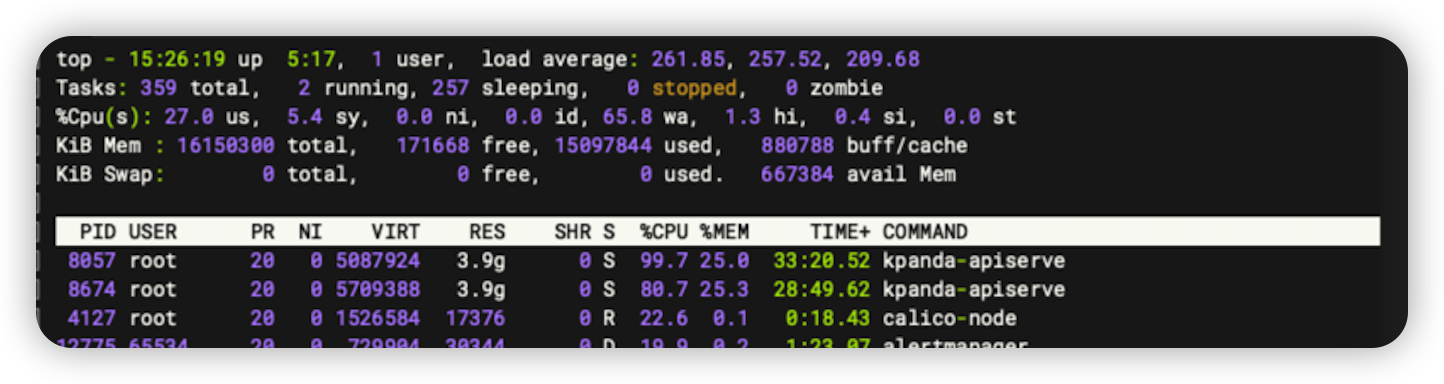
某个节点磁盘读吞吐异常、CPU workload 很高¶
异常信息
解决方式
如果 es 在此节点,可以将ES进程杀掉恢复。
数据写入 Elasticsearch 时报错 status:429¶
完整的报错信息如下:
[2023/03/23 09:47:16] [error] [output:es:es.kube.kubeevent.syslog] error: Output
{"took":0,"errors":true,"items":[{"create":{"_index":"insight-es-k8s-logs-000067","_type":"_doc","_id":"MhomDIcBLVS7yRloG6PF","status":429,"error":{"type":"es_rejected_execution_exception","reason":"rejected execution of org.elasticsearch.action.support.replication.TransportWriteAction$1/WrappedActionListener{org.elasticsearch.action.support.replication.ReplicationOperation$$Lambda$7002/0x0000000801b2b3d0@16e9faf7}{org.elasticsearch.action.support.replication.ReplicationOperation$$Lambda$7003/0x0000000801b2b5f8@46bcb787} on EsThreadPoolExecutor[name = mcamel-common-es-cluster-masters-es-data-0/write, queue capacity = 10000, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@499b0f50[Running, pool size = 2, active threads = 2, queued tasks = 10000, completed tasks = 11472149]]"}}},{"create":{"_index":"insight-es-k8s-logs-000067","_type":"_doc","_id":"MxomDIcBLVS7yRloG6PF","status":429,"error":{"type":"es_rejected_execution_exception","reason":"rejected execution of org.elasticsearch.action.support.replication.TransportWriteAction$1/WrappedActionListener{org.elasticsearch.action.support.replication.ReplicationOperation$$Lambda$7002/0x0000000801b2b3d0@16e9faf7}{org.elasticsearch.action.support.replication.ReplicationOperation$$Lambda$7003/0x0000000801b2b5f8@46bcb787} on EsThreadPoolExecutor[name = mcamel-common-es-cluster-masters-es-data-0/write, queue capacity = 10000, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@499b0f50[Running, pool size = 2, active threads = 2, queued tasks = 10000, completed tasks = 11472149]]"}}},{"create":{"_index":"insight-es-k8s-logs-000067","_type":"_doc","_id":"NBomDIcBLVS7yRloG6PF","status":429,"error":{"type":"es_rejected_execution_exception","reason":"rejected execution of org.elasticsearch.action.support.replication.TransportWriteAction$1/WrappedActionListener{org.elasticsearch.action.support.replication.ReplicationOperation$$Lambda$7002/0x0000000801b2b3d0@16e9faf7}{org.elasticsearch.action.support.replication.ReplicationOperation$$Lambda$7003/0x0000000801b2b5f8@46bcb787} on EsThreadPoolExecutor[name = mcamel-common-es-cluster-masters-es-data-0/write, queue capacity = 10000, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@499b0f50[Running, pool size = 2, active threads = 2, queued tasks = 10000, completed tasks = 11472149]]"}}}]}
解决方式
-
方式 1:产生 429 错误的原因是 Elasticsearch 写入并发过大, Elasticsearch 来不及处理导致,可以适当降低写入并发并控制写入量。
-
方式 2:在资源允许的情况下,可以适当调大队列大小
方式 1 和方式 2 可以配合使用。